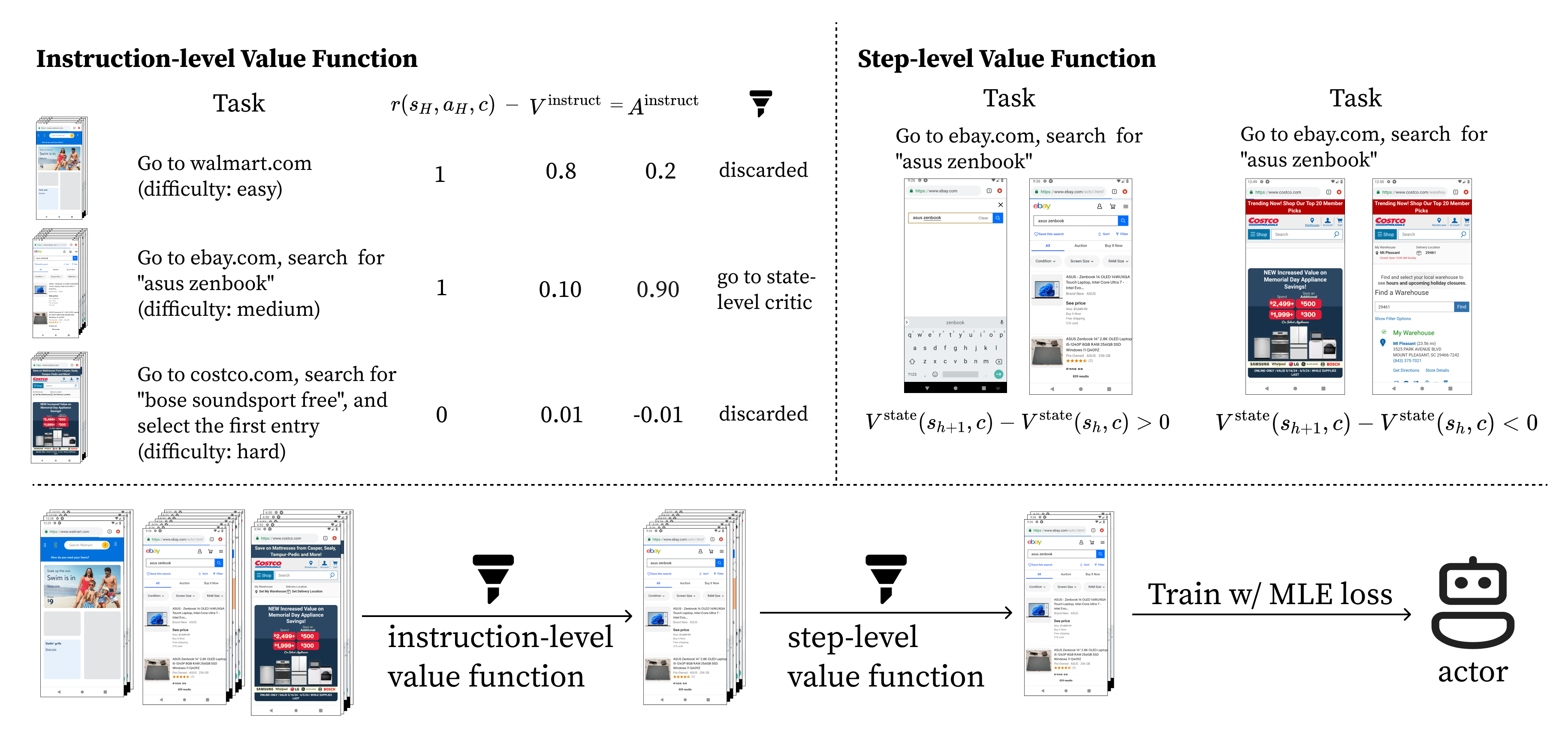
Autonomous Evaluation
Our main results are autonomously evaluated with Gemini-1.5-Pro. We also manually evaluate on some subsets and finds that the autonomous evaluation results highly align with manual evaluations with an average difference less than 3%:
Failure Mode Analysis
While all the types of failure modes benefit from offline and offline-to-online RL training, the most consistent and significant reduction is for the failure mode of failing to recover from mistakes. By training on autonomously-collected rollouts, our agent DigiRL is able to learn from its own mistakes and reduces failures to recover over training.